Data
Feb 09, 2023
Designing Enterprise Data Architecture: Your Data Culture Journey & 5 Best Practices to Apply Along the Way





In today’s modern tech industry, data is one of the most valuable resources a company can use to improve the quality of their business. With the increased popularity of cloud computing technologies such as Amazon Web Services (AWS), Google Cloud Platform (GCP), Snowflake, and Microsoft Azure, processing and analyzing data has never been more accessible and cost efficient.
Despite these advancements, there is still confusion surrounding the best data architecture practices and frameworks. By implementing a modern enterprise data architecture, businesses can make more data driven decisions and adapt their business model to keep up with changing trends. Here we’ll outline enterprise data architecture principles and a data journey map.
What is Enterprise Data Architecture?
Enterprise data architecture is essentially a plan for a business, usually designed by a data architect, that maps the entire data flow process; it ranges from the initial data ingestion to the eventual analysis of it through a business intelligence (BI) tool, such as Microsoft PowerBI or Amazon QuickSight, or through the development of machine learning models.
It’s important that the data architecture framework includes all applicable tools and technologies associated with the data ecosystem, such as data sources, data transformations, storage, and hardware. Cloud computing platforms enable seamless integration of these data technologies into data architecture, as well as ease of integration into the overall business’ data architecture strategy.
Any company that relies heavily on data should have a concrete, overarching enterprise data architecture framework to maximize their potential and efficiency as a business.
The Data Culture Journey and The Data Platform Structure
Credera has designed a data culture journey map that highlights how organizations will mature as they move along their own data culture path. As the organization matures, their cultural approach to data moves forward or to the right on the map below.


Finding Your Place on the Journey
Each business will start at a different point in the journey, as defined by the number of data products that can be delivered in parallel without sacrificing quality or introducing excessive technical debt. One key component that defines your stage of the journey is the maturity of a company’s current data architecture. Identifying where your business stands in the journey is important to identifying the next steps in the journey.
For example, a company with existing legacy technologies may already have legacy data sources but may be able to glean additional value from them, while newer businesses still need to identify and establish appropriate data sources and figure out how to scale up their data operations. Once a company’s position on this data maturity map is established, it will be easier for the rest of your technology to align along the way.
At Credera, we believe the key to enterprise data architecture comes from having a product mindset. Throughout a company’s data journey, they can discover the best utility and assets that can be built from a foundational data platform. This allows an organization to scale up when needed and deliver data products when demand changes
Defining Your Terms
With an abundance of services offered by a multitude of technology companies, it can be challenging to navigate through all the buzzwords associated with data architecture. The data vendor ecosystem is crowded and complex.
Additionally, many companies use the same buzzwords (lakehouse, mesh, DataOps) to have different meanings to suit their platform implementation, which can be intimidating to encounter at first.
The common core platforms for a modern enterprise data architecture are the following:
Amazon Web Services (EMR, Lakeformation, Glue, Redshift)
Google Cloud Platform (DataProc, DataFlow, BigQuery)
Microsoft Azure (HDInsight, Synapse Analytics)
Databricks
Snowflake
The first step towards building a strong Enterprise Data Architecture is to choose the products that are right for your company’s infrastructure. Each of these technologies have unique advantages and can be used effectively in building your company’s enterprise data architecture solution.
Establishing State of the Art Enterprise Data Architecture
After picking the right products to center the data architecture around, additional consideration must be given to how the company manages these systems. As an organization progresses along its data culture journey, the amount of data it processes and analyzes can increase exponentially. Therefore, the major reason to update a company’s data architecture is to mitigate any ongoing or future confusion surrounding the data processing practices.
Most companies looking to modernize their data architecture start because of the pain from being in one of two organizational positions:
Silo Anarchy, which can lead to multiple answers for the same question existing in independent data silos, or worse data breaches due to lack of overarching control structures for sensitive data.
Legacy Data Warehouse, which are too controlled and inflexible to update, resulting in long timeframes to answer seemingly basic new questions, sometimes coupled with a data lake that is not controlled enough, leading to the same problems as Silo Anarchy.
Common Legacy Data Architecture

As a business matures along the data culture journey, implementing more controlled and user-accessible structures will become necessary for efficient operations.

Three major goalposts in the journey to define a state-of-the-art enterprise data architecture include:
Establishing a data lakehouse as part of your data platform
Incorporating Data Reliability Engineering
Progressing the enterprise data architecture towards a Harmonized Mesh
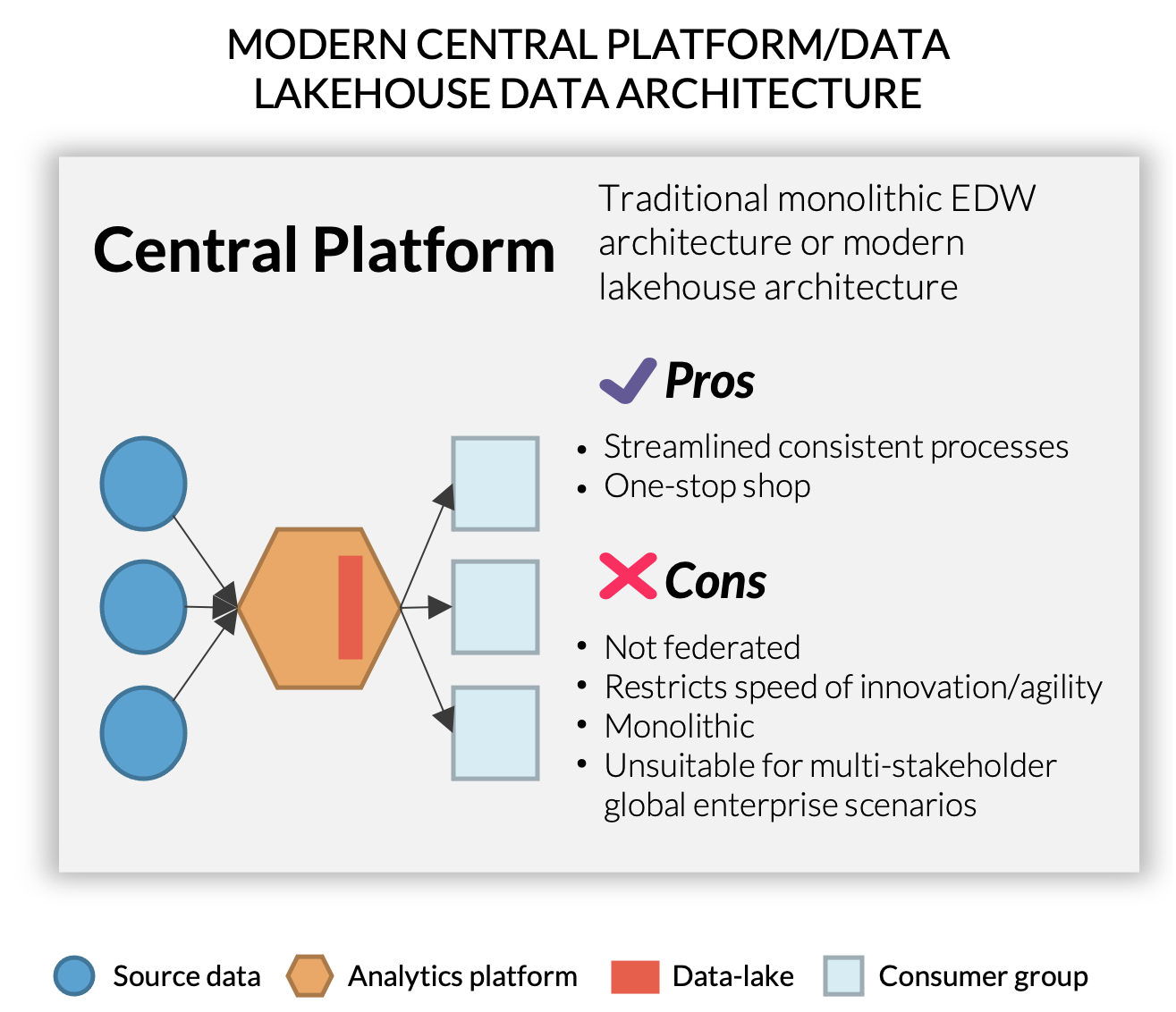
Establishing the Data Lakehouse


A data lakehouse is a system that will alleviate the challenges of both silos and swamps by providing a single central analytics ecosystem to support all types of data products, regardless of data and system complexity.
A data lakehouse, an intermediate step on the data culture journey, is a combination of data warehouses and data lakes. They can combine on premises data storage with cloud computing services (lakes + cloud warehouses) to create the easiest and most accessible framework for a data platform. In doing so, they leverage both the flexibility and rapid scalability of a data lake with the centralized governance structure of a data warehouse.
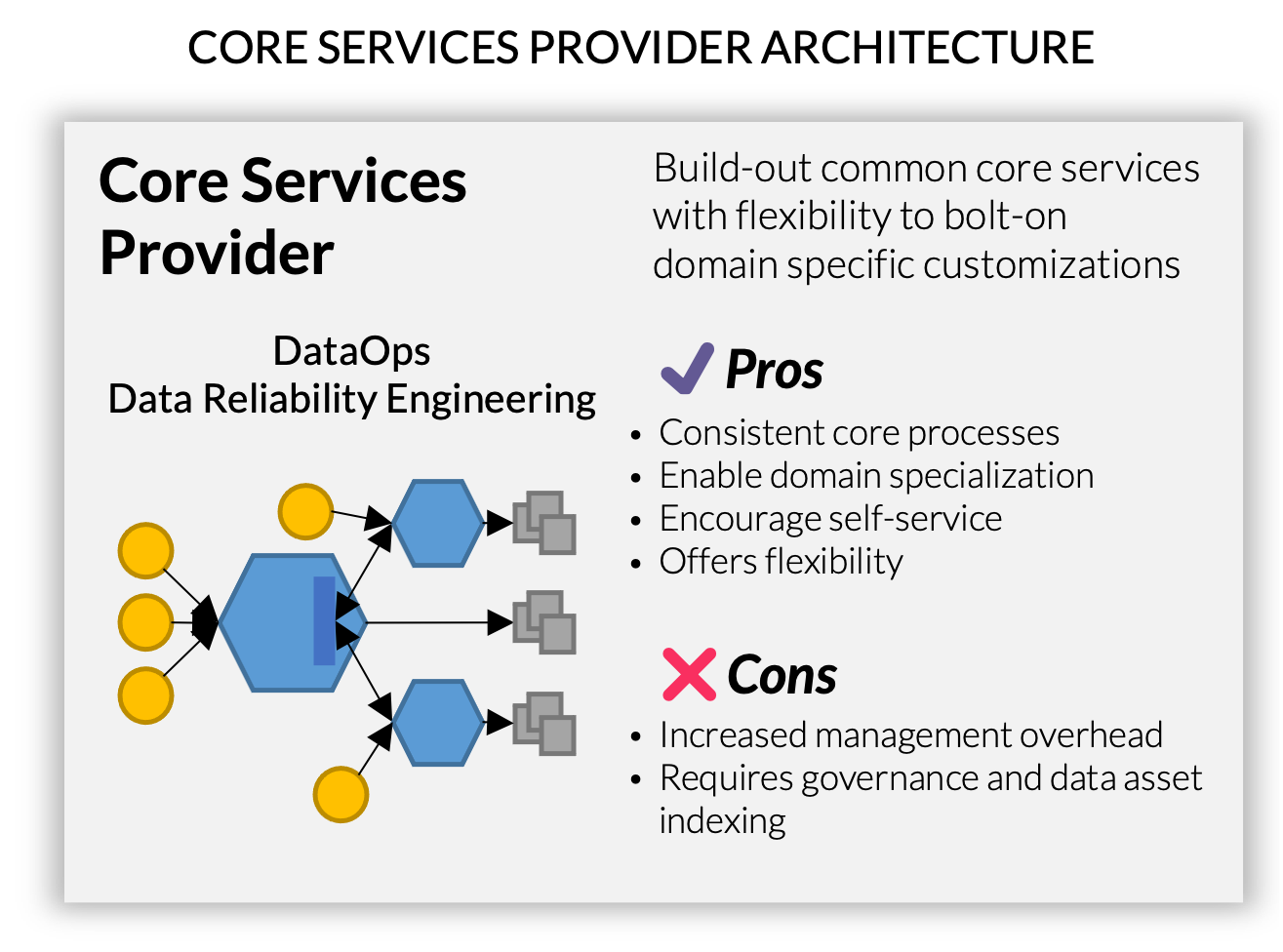
Incorporating Data Reliability Engineering
Maximizing value from a data lakehouse still involves centralized upkeep of the data system. The most sustainable organizational approach is to task a Data Reliability Engineering (DRE) team with ensuring all best practices are continuously upheld by monitoring your businesses enterprise data architecture and redesigning it as needed. A DRE team will help with industrializing your entire data platform, and from there, running at scale when demands increase as your business grows.
Additionally, having a DRE team enables data observability, exploring data behavior and patterns that doesn’t need to be defined in advance, a step beyond monitoring from set metrics or logs. Observability is a necessary foundation to the overall enterprise data architecture, as it allows your DRE to identify unexpected issues on your platform and address them in a reasonable timeframe.


By leveraging these skilled practitioners to develop platform components standards and patterns for common data scenarios and layering in additional engineering rigor upfront (multiple environments, testing standards, end-to-end monitoring), there is much less risk of the data system devolving into a data swamp. From there, the responsibility to develop data products can be outsourced to groups closer to the business.
This decentralized approach speeds up the standing up new data products and puts the process in the hands of teams who understand the data best. Furthermore, it staves off the risk of centralized data warehouse upkeep becoming a bottleneck to deriving valuable answers from data.
For organizations where most business units use data in similar ways, the data lakehouse coupled with a strong organizational process around a Data Reliability Engineering team is likely sufficient for a sustainable data architecture. However, for organizations with teams that need to run individually specific analyses on the data, a more flexible data architecture is required.
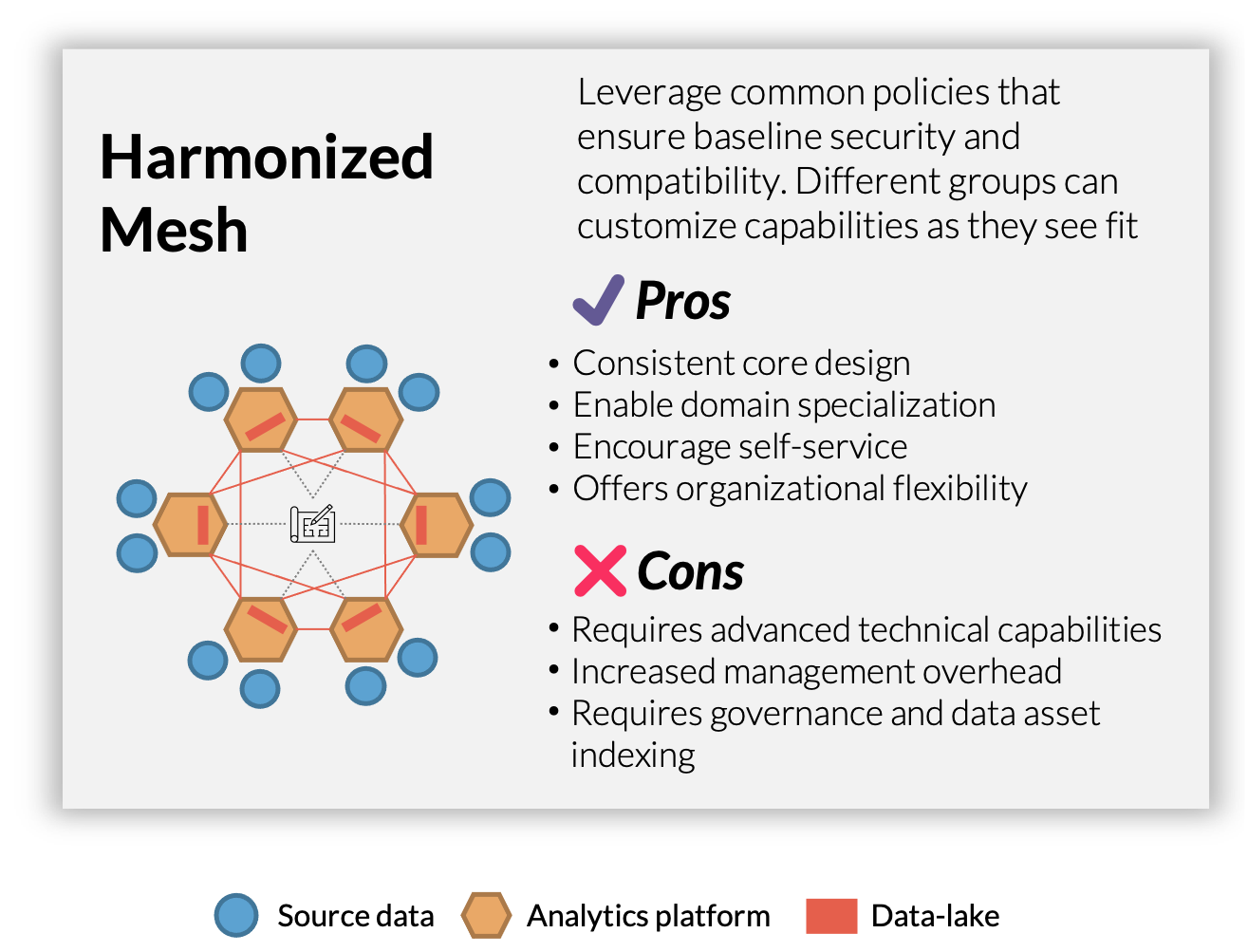
Establishing a Harmonized Mesh


Establishing a Harmonized Mesh is the ultimate goal for the Enterprise Data Architecture journey. To fully maximize the value of data across different teams, many organizations require a system that enables multiple teams within a company to leverage a similar set of data, but run individualized analysis and modifications on it. The challenge is if one team starts modifying the data to meet its own needs, it can be difficult for other teams to revert back to the version they require. A Harmonized Mesh centralizes data governance and management of the data and distributes it across multiple domain partitions. This ensures that base data sources remain available and usable for all teams, while each team has the flexibility to customize the data within their domain.
Establishing a Harmonized Mesh can be difficult because maintaining security and data compatibility requires plenty of organization when multiple teams need to access and manipulate the data. This is why establishing the Data Reliability Engineering team to enforce the structure of the base sources and manage the complexity of the data ecosystem is an essential prerequisite to attaining the Harmonized Mesh.
Other Enterprise Data Architecture Best Practices
Once the core architecture is set up, other best practices should be followed to use the data effectively. These include the following five:
Define your business’s objective: By defining your business’s objective, you can focus on specific data that would be most beneficial to analyze and ignore any extraneous sources.
Implement flexible data ingestion: Allowing for flexible data ingestion would allow your data pipeline to take in many different forms of raw data (CSV, JSON, XML, etc.) that can be processed in BI tools.
Remove internal data silos: Removing data silos would allow data to be shared freely between internal organizations and improve efficiency in the overall data processing pipeline.
Automate the process: Automation of the process would require only an initial setup of the enterprise data architecture framework and then simply require observation over the pipeline in case there are hiccups.
Maintain the integrity of the data: This is one of the most important practices because poor quality data can lead to suboptimal business decisions and poor data governance. Ultimately, this can lead to compliance issues.
Enforcing these practices throughout your data architecture will enhance the overall data analysis process at various stages.
Implementing Enterprise Data Architecture
Designing Enterprise Data Architecture can be a daunting task for a new business, or even for an established business looking to improve upon their legacy data tools. This article covered key components and patterns to build an Enterprise Data Architecture and evolve it as you progress in your Data Culture Journey.
However, it requires a lot more nuance to define a “shovel ready” architecture that is ready for implementation. Here at Credera, we have seasoned professionals who can partner with a business to improve their data practices. If you are interested in learning more, feel free to reach out to us at marketing@credera.com.

Data
Dec 03, 2024
Ten ways to improve your data strategy
A data strategy establishes a set of principles that the organization can use to guide data investments and help to energize...
Technology
Oct 21, 2022
Technically Minded | Data Architecture vs. Application Architecture: Where Should...
Credera's Chief Data Officer Vincent Yates and Chief Technology Officer Jason Goth discuss the need for a data-first...


Data
Aug 01, 2022
Data Quality Series Part 5: Automating Data Quality for Modern Architecture
By managing data quality from planning through development and into production, organizations are able to move data quality...



Contact Us
Ready to achieve your vision? We're here to help.
We'd love to start a conversation. Fill out the form and we'll connect you with the right person.
Searching for a new career?
View job openings